

Internet Fundamental Principle: If It’s Closer, It’s Faster. Always — in Solana too.
Internet Fundamental Principle: If It’s Closer, It’s Faster. Always — in Solana too.

Many traders and projects seeking the “fastest environment” first look at average latency.
It can be useful as a reference for comparison, but if what you are aiming for is zero-slot trading — in other words, the 200–400ms range — you will never get it from average latency.
Solana is globally distributed, and intercontinental communication inevitably incurs hundreds of milliseconds of delay.
As long as you are focused on an average that includes such delays, the speed you truly need will remain out of reach.
In reality, the outcome is decided by shaving off just a few milliseconds within your own region, where close-range communication takes place.
Recovering the Intuition of Speed
When thinking about networks, imagine yourself driving a car. The starting point is your home, the destination is your office. A short commute is simple and fast, with little risk of accidents or traffic.
A long trip, by contrast, involves intersections, highways, tunnels — and somewhere along the round trip, congestion is likely to occur.
The internet works the same way. The farther away the server, the more hops are required, and the round-trip time becomes more variable. Bringing the destination closer is the shortest route to achieving both maximum speed and stability.
Why Averages Won’t Win
In Solana, leaders rotate to produce blocks, so how physically close you are to the current leader determines the outcome. Leaders are distributed globally, and it is not uncommon for them to be located on different continents.
Intercontinental communication exceeds 100ms in ping, and swells to several hundred milliseconds for streams.
No matter how much you polish an average that includes such delays, it won’t translate to real performance. You simply cannot catch up in intercontinental slots.
The point is not to chase averages, but to focus on your own region and minimize round trips within that scope. Fighting over a few milliseconds at short distance is the only practical approach with a real winning edge.
For reference, here are baseline round-trip values by distance:
| Distance | Round-trip Ping (approx.) |
|---|---|
| Same network | ~0.1ms |
| Private connection | ~0.2ms |
| Same data center | ~0.3ms |
| Same city | ~1ms |
| Neighboring country | ~5–10ms |
| Intercontinental | ~100–300ms |
Actual effective latency grows further depending on communication method due to protocol overhead and maintenance costs:
| Method | Latency multiplier | Notes |
|---|---|---|
| Ping (ideal) | 1× | Reference lower bound only |
| POST (single send) | ~2–3× | Round-trip control, retries, TLS |
| Stream | ~5× | Persistent connection, congestion control, buffers |
How to Measure “Closeness”
Closeness should be measured with data, not intuition. Start by checking the current epoch position. With RPC getEpochInfo, get the latest epoch data, elapsed slots, and remaining slot counts.
Next, use getRecentPerformanceSamples to estimate recent average slot times. Multiplying average slot time by remaining slots gives a rough estimate of how many seconds until transition — useful for preparation and switching plans.
As transition nears, prepare to retrieve the target leaders with getSlotLeaders.
The cluster node list is available with getClusterNodes, so you can cross-reference leader data with node information, using public IPs or gossip addresses to infer geographical scheduling.
One caution: IP geolocation has errors and delays, so estimates may be wrong. After mapping locations, always ping from each site to directly measure baseline round-trip delays.
Networking is like a road trip — not just distance, but the chosen route affects arrival time. Ping shows, simply, how congested today’s roads are.
Don’t rely on a single measurement; take multiple samples over short intervals and use the median to reduce noise.
Do not discard results after use. Accumulate round-trip data and mappings per site in your own database, and update them incrementally with lightweight workers on each epoch transition. This stabilizes operations and speeds up decision-making.
Application Placement Defines Latency
Speed is not determined by server specs alone. The location of the application matters just as much.
As an extreme example, monitoring what happens in Frankfurt from Tokyo is disadvantageous. The round-trip latency alone creates accumulated delay, always putting you behind.
Deploy resources at each site, completing receive-and-process locally, or bypassing to the next site via the shortest route. This structure improves both coverage and responsiveness.
VPS Deployed in the Same Network
Our VPS instances are deployed per region in the same network as Solana dedicated endpoints, cutting external communication and achieving the shortest round trips.
They can be deployed quickly and in small scale per region. Even distributing just 1–2 core workers reduces effective latency and increases resilience against missed opportunities.
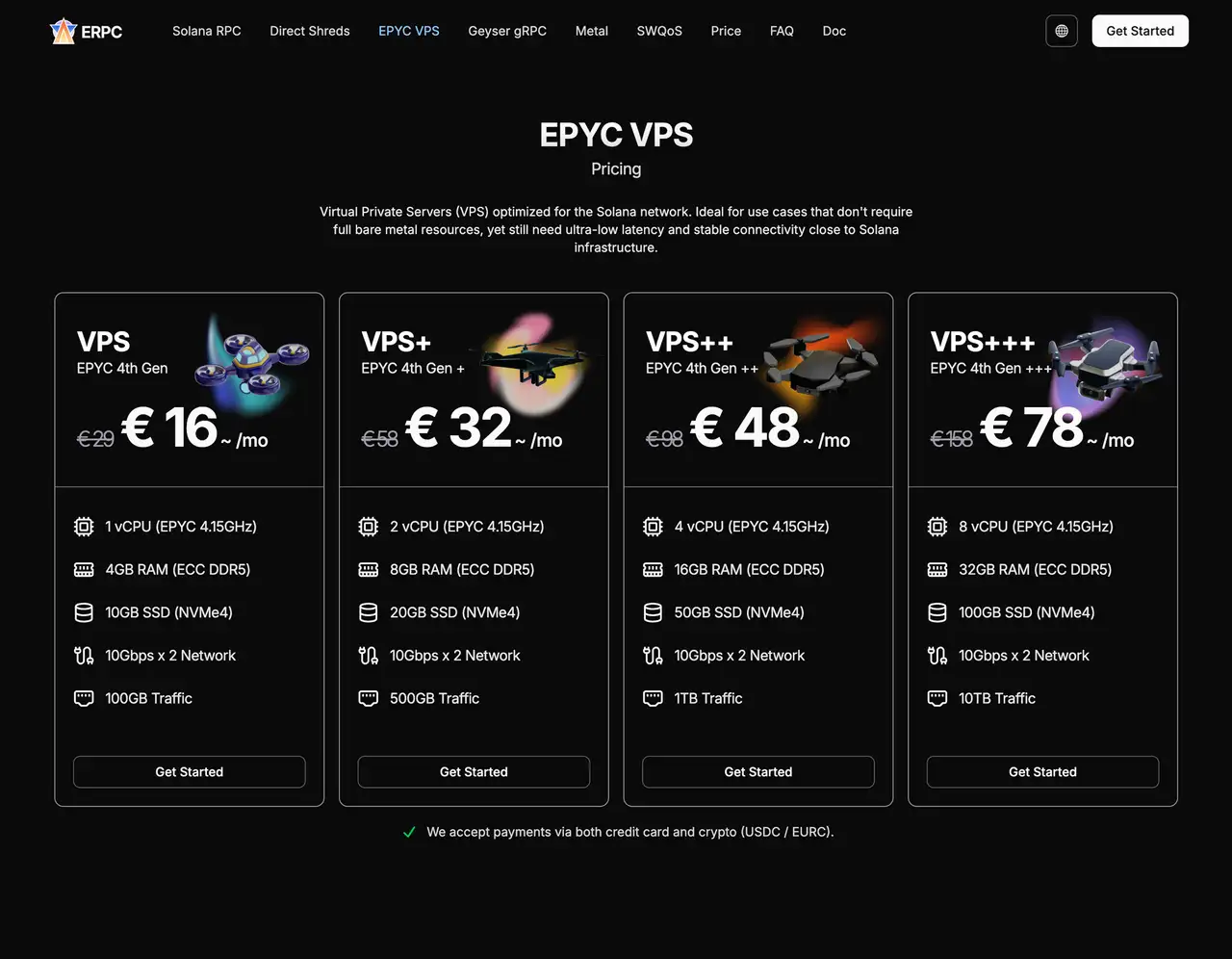
Upcoming Release in September 2025: “SUPER EPYC VPS”
This month, starting from the most popular Frankfurt region, we plan to release “SUPER EPYC VPS,” using data-center CPUs with market-leading 5.7GHz clock speeds.
Adopting the latest generation CPUs for VPS products is not common practice, making availability limited. For those seeking the fastest VPS, it will be a strong option.
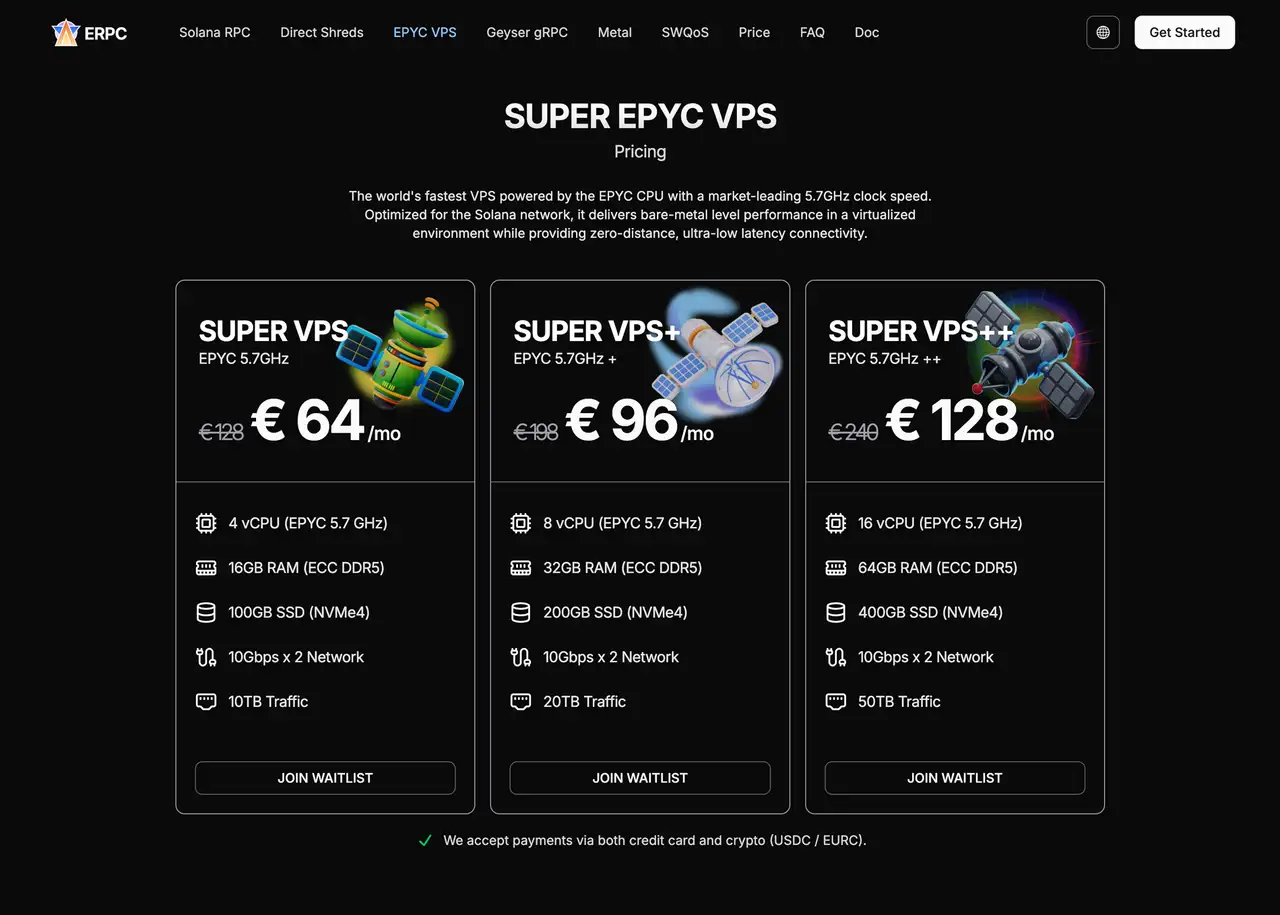
For Maximum Quality and Speed: Bare Metal
While VPS divides a physical server into virtualized parts, bare metal servers dedicate all CPU, memory, disk, and network bandwidth to you alone.
This makes it easier to sustain stable, high performance even during peak times, ideal for Solana applications requiring consistently low latency.
For Solana use cases, Ryzen CPUs are especially popular, achieving consumer-grade maximum clock speeds of 5.7GHz. EPYC is designed to minimize virtualization overhead, while Ryzen is designed to maximize single-thread performance without virtualization. Choose according to your use case.
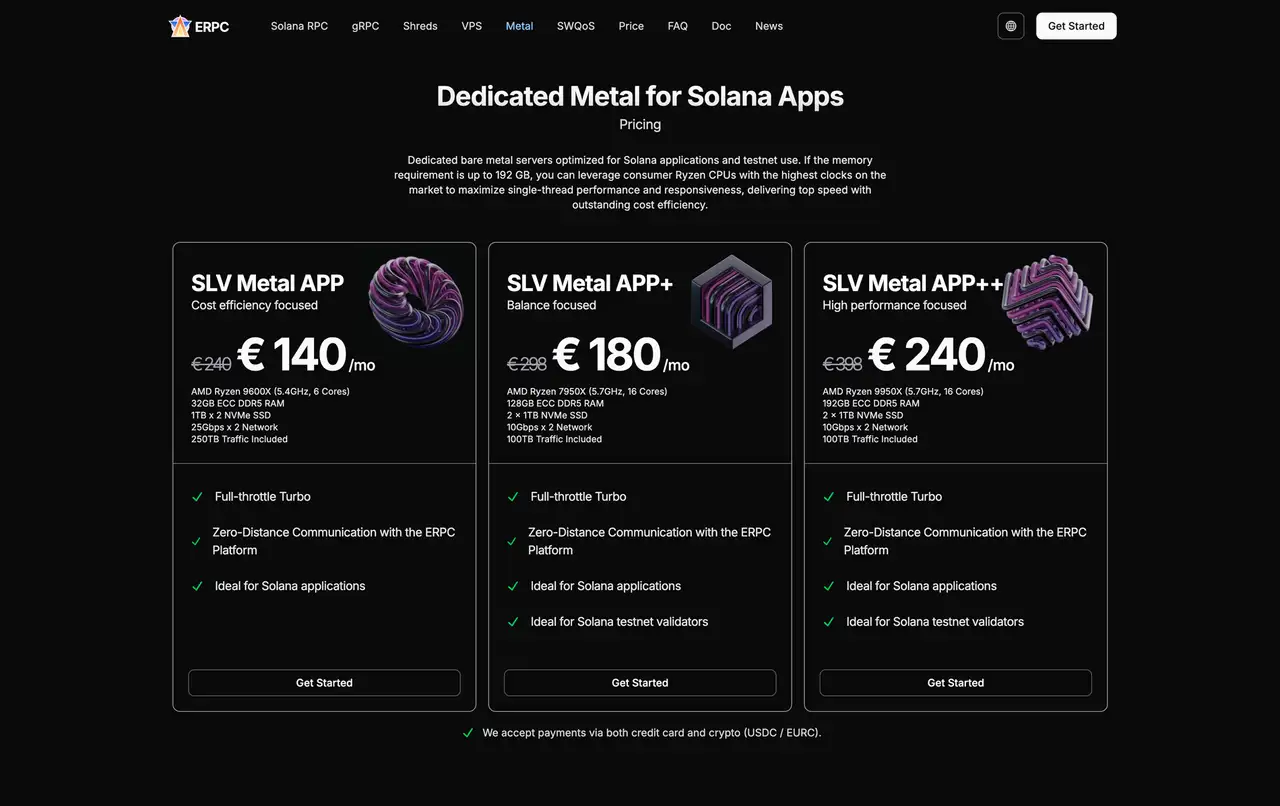
Challenges ERPC Solves
- Transaction failures and latency fluctuations common in typical RPC environments
- Performance limitations imposed by many infrastructure providers
- The significant impact of network distance on communication quality
- Limited access for small projects to high-quality infrastructure
Details about products, free trials, onboarding process, dedicated setups, inventory inquiries, and waitlist participation are available via Validators DAO official Discord:
- ERPC official site: https://erpc.global/en
- Validators DAO official Discord: https://discord.gg/C7ZQSrCkYR
We will continue our R&D efforts, working to stabilize supply and expand our lineup, delivering value to more projects worldwide.
Thank you for your continued support.
News


